Best Textual Data Format: XML, JSON, YAML or CSV?
What is the best textual format to use?
If you ran a poll, JSON would win by a huge margin. XML is still the star of the enterprise world. CSV often gets used when developers don’t want to build a full Excel exporter. And YAML tends to be the black sheep of the family. It's powerful but is often feared, and mostly used in DevOps tooling.
So what actually goes into deciding which format to use? And is JSON really the best choice?
Let’s add some structure to this decision.
Use cases
As you have no doubt realised, there is no one-size-fits-all solution. Every format has its pros and cons, and different use cases call for different trade-offs.
Consider the following use cases:
- CRUD API – e.g., POST /resource or the RPC equivalent.
- Event Streaming – e.g., a server pushing events over WebSockets/SSE, or a message broker delivering events to subscribers.
- Configuration – human-edited files used to configure applications and tools.
- Data Dump – transferring large volumes of data between systems.
- Report Dump – generating human-consumable reports.
- Log Files – recording application/system events, possibly for long-term retention.
What matters?
Instead of categorically assigning formats to use cases, it’s more useful to think relatively.
For example, saying “XML has high processing overhead” is only meaningful relative to formats in this post. Compare XML to an Excel workbook—which is a zip containing multiple XML files plus binary blobs—and suddenly XML doesn’t look so heavy.
Absolute scales don’t help much. Relative scales do.
Readability
Readability often plays a key role. When making API calls, being able to glance at request/response payloads is extremely helpful. When transferring huge datasets between systems, readability stops mattering—efficiency takes over.
We can rank use cases by readability, from less important to more important:
- Data Dump
- Log Files
- Event Streaming
- CRUD API
- Report Dump
- Configuration
Configuration files are heavily human-oriented; report dumps also need strong readability.
Ranking the formats by readability, from lower to higher:
- JSON
- XML
- YAML
- CSV
While XML is placed below YAML, it isn't dramatically less readable. It’s simply less familiar outside enterprise environments. You could make the argument for the opposite order - that XML is so verbose that it hurts readability.
Processing Overhead & Feature Rich
Processing overhead grows with complexity and feature richness.
For example, report dumps are mostly tabular and few features are needed. Configuration files often require comments, anchors, references, multi-line strings, etc.—more features, more overhead.
Use cases ranked by processing overhead (lower → higher):
- Report Dump
- Event Streaming
- CRUD API
- Log Files
- Data Dump
- Configuration
Formats ranked similarly (lower → higher):
- CSV
- JSON
- XML
- YAML
Plotting readability against complexity for both use cases and formats yields roughly aligned curves:
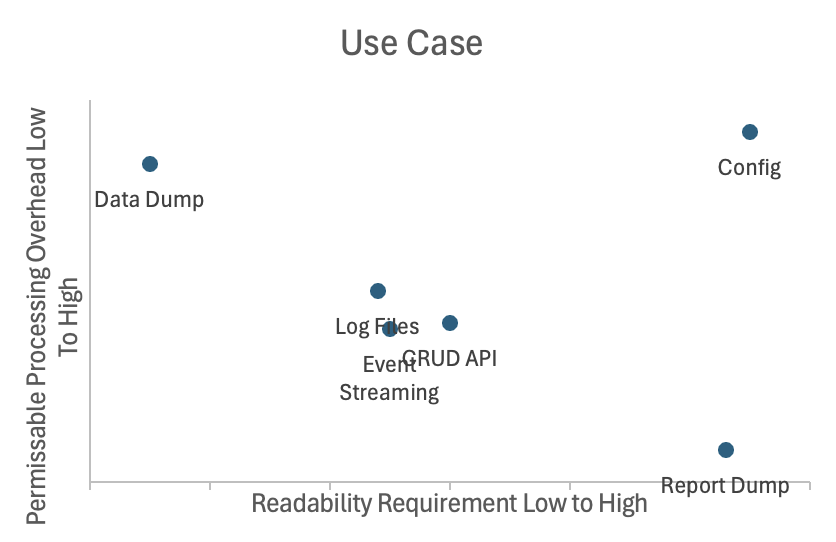
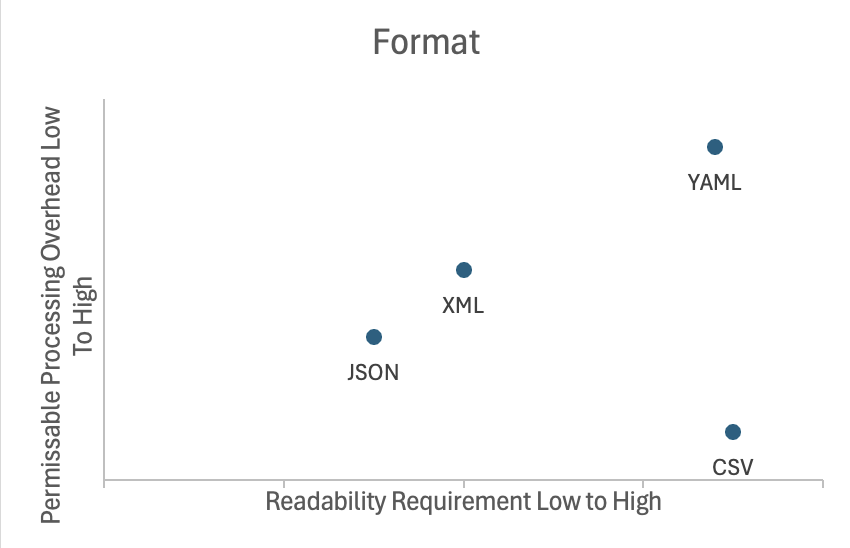
I had to move some data points that are similar closer together in a way that makes sense.
This also reveals something important: None of these text-based formats are ideal for very large data dumps. They are built for readability, not raw efficiency.
Efficiency
I saved this one for last. Especially because if you are using text based formats, you are not supposed to be worrying about efficiency. But I have some interesting numbers to share none the less.
I used a random 100 KB file from a recent investigation— 200 rows, 16 fields—small enough to handle easily but large enough to show differences. I converted it to JSON, YAML, XML, CSV, and also SQL COPY statements.
Then I measured:
- Size with whitespace
- Size without whitespace
- Size compressed using gzip -9
This is ordered from least efficient to most efficient:
| Format | Size with whitespace | Size without whitespace | Size compressed (gzip -9) |
|---|---|---|---|
| XML | 157,967 | 130,246 | 23,508 |
| YAML | 98,698 | 23,152 | |
| JSON | 111,290 | 92,929 | 23,046 |
| SQL | 53,948 | 22,092 | |
| CSV | 41,646 | 21,284 |
Findings:
- XML is by far the most verbose and least efficient.
- YAML is surprisingly verbose too—better than XML, worse than compact JSON.
- JSON (minified) is meaningfully smaller than YAML.
- SQL COPY statements compress very well.
- CSV is the smallest both raw and compressed.
- After gzip compression, the differences shrink dramatically—XML becomes only ~10% larger than CSV.
War story
Recently, I had to port a report-dump feature from a backend-of-backend service to customer-facing APIs.
The original Rails implementation exported CSV. It struggled with anything over ~15 days of data—slow, crash-prone.
I rewrote it in Node, paginating JSON over REST. Performance improved dramatically and multi-month ranges became feasible. We were even able to show key summary stats the client needed on the front-end while data was loading. But for anything over 6 months, large JSON responses caused the front-end client to crash while collating pages and converting JSON → CSV.
In the latest iteration, I switched to streamed, compressed CSV over a single request. The backend can now stream years of data efficiently and progressively. Year range dumps that previously crashed now complete in 1–2 minutes.
This is not to say it would not be possible with XML or JSON. I can imagine streaming a partial XML / JSON documents with a sax parser on the client side to achieve the same result. However, this ended up being the least complex solution that met all the requirements.